
Voynich Reconsidered: a research strategy
In my book Voynich Reconsidered (Schiffer Publishing, 2024), I proposed that in any attempt to find meaning in the Voynich manuscript, the researcher should adopt a strategy.
My approach to the formulation of a research strategy was as follows: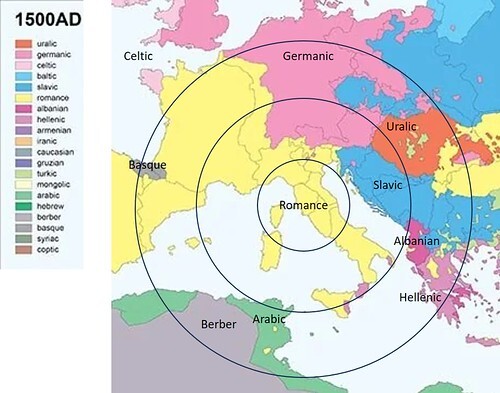
A map of the main language groups in Western Europe in the year 1500, with concentric circles of arbitrary radius centred on Frascati, Italy. Image credit: blogen, www.theapricity.com; graphics and annotations by author.
Permutations
The implementation of the strategy that I outlined above requires the testing of multiple mappings. The permutations that I have conceptualised so far are as follows:
My approach to the formulation of a research strategy was as follows:
• I attempted no interpretation of the illustrations, nor of any visual similarity between the Voynich text and known medieval scripts such as Uncial or Beneventan. I believe that professional medievalists, such as Dr Lisa Fagin Davis and D N O'Donovan, have approached the manuscript from this perspective, but I have no expertise in this area.
• I focussed on the text, as a database permitting a computational and statistical approach.
• I adopted the hypothesis that the text possessed meaning (since I think that the converse is not amenable to proof).
• I adopted the hypothesis that the text had a precursor document or documents in a natural human language or languages.
• I thought it a reasonable assumption that (by the distance-decay hypothesis) those languages were more likely to be used within certain concentric geographical radii of Italy, where Wilfred Voynich claimed to have discovered the document.
• I assumed that the producer or author of the manuscript had been sufficiently wealthy to employ a team of professional scribes for months or years, and to pay for the materials and supplies. As such, that person would have had other interests which would preclude detailed supervision of the scribes. Therefore, I thought it probable that the producer had given the scribes a set of simple instructions which they could follow until completion of the manuscript.
• My objective (with due recognition of Occam's Razor) was to reconstruct those instructions, as simply as possible.
A map of the main language groups in Western Europe in the year 1500, with concentric circles of arbitrary radius centred on Frascati, Italy. Image credit: blogen, www.theapricity.com; graphics and annotations by author.
Permutations
The implementation of the strategy that I outlined above requires the testing of multiple mappings. The permutations that I have conceptualised so far are as follows:
• glyph definitionsTo my mind, the researcher who wishes to pursue a computational approach to the text needs a sufficient number of permutations, and as a corollary, sufficient computing power, to be able to test a wide range of assumptions. I have in mind a matrix of, say, ten sets of glyph definitions; three definitions of “word” breaks; and maybe ten potential precursor languages: implying at least 300 permutations. In each case, the researcher needs to do the following:
The widely used transliterations of the Voynich manuscript (for example EVA and v101) embody assumptions about what is a glyph. For example, the v101 glyph {m} is three glyphs in EVA, namely {iin}. Conversely, the three-glyph string {cth} in EVA is the single glyph {K} in v101. These are reasonable interpretations of the symbols, but they cannot be the only ones. The researcher needs multiple transliterations in which various definitions of the glyphs are applied.
• “word” definitions
All transliterations assume that glyph strings delimited by spaces or line breaks are “words” in the sense that we use the term “word” in a natural language. That is, a Voynich “word” represents an object or a concept, and can be spoken and understood. EVA seems to treat any obvious space as a word break. The v101 transliteration makes a distinction between “spaces” and “uncertain spaces”, wherein glyphs are closely spaced and we are not sure whether or not a word break is present. At the Voynich 2022 conference, Massimiliano Zattera introduced a third concept: that of “separable words”: those "words" which have no discernible internal spaces, yet can be broken up into two or more Voynich “words”. In natural languages, an analogy can be seen in compound words such as, in English, “battlefield”.
• precursor languages
Since the Voynich script is not the script of any known language, we have a multitude of possible precursor languages. I have proposed that we could apply some filters on the basis of probabilities. For example, we might assign higher probabilities to languages used within some specified geographical radii of Italy. Likewise, since the material of the manuscript is calfskin, we could assign higher probabilities to the languages of countries or regions where cattle have been widely domesticated.
• take a sufficiently large chunk of Voynich text (at least a paragraph, or a page, or longer)
• map the Voynich text (using an objective and consistent algorithm such as frequency analysis) to the candidate language
• test the resulting text strings against appropriate corpora of the candidate language, and see whether there is any clear narrative meaning
• and if not, explore the possibilities that re-ordering of the letters within words might produce narrative meaning.


No comments have been added yet.
Great 20th century mysteries

In this platform on GoodReads/Amazon, I am assembling some of the backstories to my research for D. B. Cooper and Flight 305 (Schiffer Books, 2021), Mallory, Irvine, Everest: The Last Step But One (Pe
...more
- Robert H. Edwards's profile
- 68 followers

